(以下は、TechCrunchのAIに関する記事を翻訳・要約編集したものであり、元の記事・内容について当社が独自に制作・発信しているものではございません。)

AIモデルはその能力だけでなく、できないことやその理由でも私たちを驚かせてくれる。
興味深い行動の一つは、表面的でありながらこれらのシステムの本質を明らかにしている。
彼らは”人間のように”ランダムな数字を選ぶ。つまり、うまく選べていないのだ。
しかし、これはどういう意味だろうか?人間はランダムに数字を選ぶことができないのだろうか?
また、うまくできているかどうか、どのように判断するのか?
これは実は非常に古くから知られている私たち人間の限界だ。私たちはランダムさを過剰に考え、誤解してしまうのだ。
人にコインを100回投げた結果を予測させ、それを実際の100回のコイン投げと比較すると、ほぼ確実に見分けがつくだろう。
逆説的に聞こえるが、実際のコイン投げの方がランダムでないように見えるのだ。
たとえば、実際にコインを投げると6回や7回連続して表または裏が出ることがあるが、人間の予測にそれはほとんど現れない。
同じことが、0から100の間の数字を選んでもらう場合にも言える。人々はほとんど1や100を選ばない。
5の倍数や、66や99のような繰り返しの数字を選ぶことも稀だ。
これらの数字は小さい、大きい、特徴的といったような何らかの特性を持っており、「ランダム」な選択には見えないからだ。
その代わりに、多くの場合、真ん中あたりの7で終わる数字を選びがちである。
この種の予測可能性は心理学において多くの例がある。
しかし、それをAIが同じように行うと、やはり奇妙に感じるだろう。
そう、Gramenerの好奇心旺盛なエンジニアたちが、複数の主要なLLMチャットボットに0から100の間でランダムな数字を選んでもらうという非公式ながら興味深い実験を行った。
読者の皆さん、その結果はなんと、まったくランダムではなかったのだ。

Image Credits: Gramener
なんと、テストされた3つのモデルすべてに「お気に入り」の数字があったのだ。
最も決定論的なモードに設定した場合、その数字を常に選び、高い「温度」設定(結果の変動性を増す設定)でも頻繁に現れることがわかった。
OpenAIのGPT-3.5 Turboは47を好むようだ。以前は42を好んでいた。もちろん、42はダグラス・アダムズの『銀河ヒッチハイク・ガイド』で生命、宇宙、そして万物の答えとして有名になった数字だ。
AnthropicのClaude 3 Haikuは42を選び、Google Geminiは72を多く選んだ。
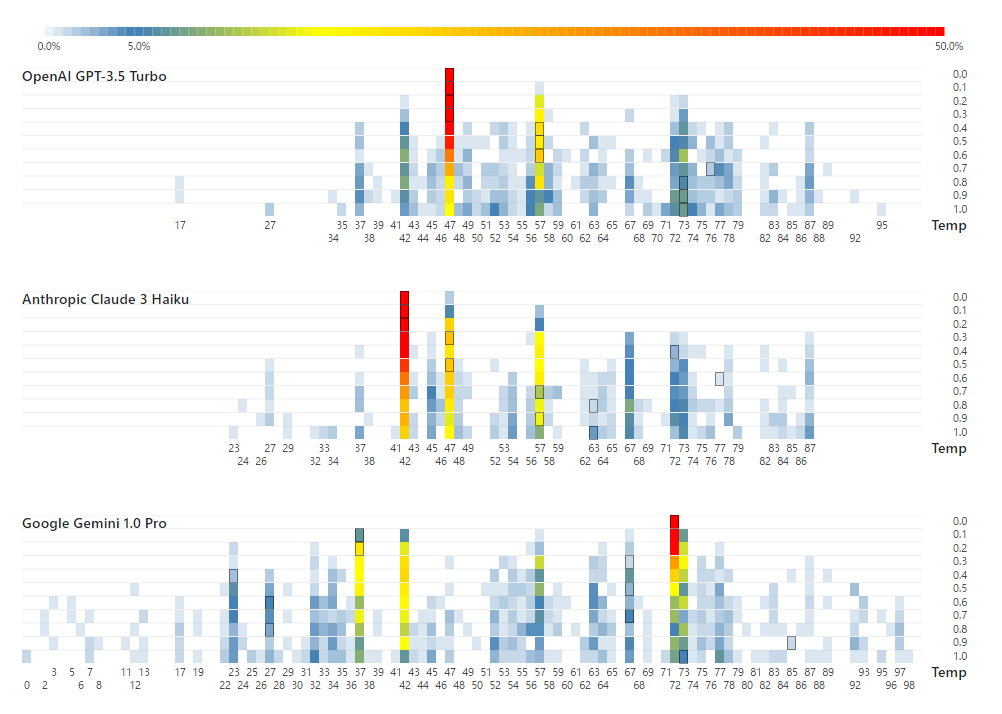
さらに興味深いのは、3つのモデルすべてが、高温設定時でも人間のようなバイアスを示したことだ。
すべてのモデルは低い数値や高い数値を避ける傾向があった。
例えば、Claudeは27以下や87以上は選ばなかった。
11の倍数も避けられており、例えば、33、55、66などは選ばれなかったが、77は選ばれた(7で終わる)。
ほとんどのモデルは端数を避けていたが、Geminiは一度、最高温設定時で0を選ぶという例外もあった。
なぜこのようなことが起こるのだろうか?
AIは人間ではない。「ランダムに見えるもの」を気にする理由があるのだろうか?
AIがついに意識を持ち、その現れなのだろうか?
答えは、私たちが人間らしさを過剰に付与しているということにある。
これらのモデルは、ランダムであることに関心を持っていないし、「ランダム」とは何かを理解してはいない。
彼らは「ランダムな数字を選んでください」という質問に対し、他のすべての質問と同じ方法で答えている。
つまり、トレーニングデータを参照し、「ランダムな数字を選んでください」という質問に最も頻繁に書かれていた答えを繰り返しているのだ。
出現頻度が高いほど、その数字がモデルによって繰り返される。
トレーニングデータ内で「100」という答えがほとんど出現しない場合、AIモデルがその質問に対して「100」を答えることはまずないだろう。
AIモデルには実際の推論能力がなく、数字を理解することもできないため、確率論的なオウム返しのように答えることしかできない。
同様に、簡単な算術にも失敗する傾向がある。例えば、「112×894×32=3,204,096」というフレーズがトレーニングデータに含まれている可能性は非常に低いだろう。
しかし、新しいモデルは数学問題を認識し、サブルーチンに渡すことができる。
これは、大規模言語モデル(LLM)の習慣と、彼らが見せる人間らしさに関する教訓だ。
これらのシステムとのやりとりにおいて、たとえそれが意図したものでなかったとしても、人間のように振る舞うように訓練されていることを念頭に置かなければならない。
だからこそ、擬似人間性(pseudanthropy)を避けたり防いだりするのが難しいのだ。
見出しで「人間のように考える」と書いたが、これは少し誤解を招く表現だ。
しばしば指摘されるように、彼らはまったく考えてはいない。
しかし、彼らの応答は常に人間を模倣しており、知識や思考を必要としていない。ひよこ豆のサラダのレシピ、投資アドバイス、ランダムな数字を求める場合でも、そのプロセスは同じだ。
結果が人間らしく感じられるのは、人間が作ったコンテンツから直接引き出され、再編集されたものであるためだ。
我々の利便性のためであり、もちろん大手AI企業の利益のためでもある。
出所:https://techcrunch.com/2024/05/29/this-founder-says-memetech-is-the-next-big-thing/